| Cartas Zenner: ¿Tienes poderes extrasensoriales? | ||||||
 | Hacia 1930 Joseph Banks Rhine y su colega Karl Zenner, ambos de la Universidad estadounidense de Duke, diseñaron una forma, más o menos empírica, de averiguar y medir la capacidad extra sensorial de las personas, es decir el llamado PES o ESP (Percepción Extra Sensorial). Se trataba de la baraja Zenner. Cada baraja de estas características posee 25 cartas: 5 cartas para 5 "palos" distintos: cruz, cuadrado, círculo, estrella y olas. | |||||
| ||||||
sábado, 17 de enero de 2009
Cartas Zenner
jueves, 8 de enero de 2009
Eficiencias de los RAID (resumen)






RAID 1E
RAID 1E (striped mirroring, enhanced mirroring, hybrid mirroring)
RAID 1E -- which, depending on the vendor, is also called striped mirroring, enhanced mirroring, and hybrid mirroring -- is a RAID level that combines RAID 0's striping capabilities with RAID 1’s mirroring protection. If you’re thinking that this RAID method sounds a lot like RAID 10, you should understand one critical difference between RAID 1E and RAID 10. RAID 1E uses an odd number of disks to achieve your data protection goals while RAID 10 requires the use of an even number of disks.
Whereas RAID levels 0 and 1 each require a minimum of two disks, RAID 1E requires a minimum of three disks. Keep in mind that RAID 10 requires at least four disks. As is the case under RAID 1, RAID 1E has a 50 percent disk capacity overhead. In other words, only half of the total capacity of the array is available for use.
RAID 1E works by striping data across all of the disks in the array a la RAID 0. As you know, however, RAID 0 is less than ideal for enterprise environments since the loss ofany disk in the array results in the loss of all data stored on the array. Where RAID 1E becomes viable is in the next step, in which a copy of the data is then striped across all of the disks as well. Simply striping the data in the exact same way as the initial stripe would not be any good since copies of the data would still reside on the same disk as the original copy. RAID 1E therefore, shifts the second copy of the data over on each physical disk. Take a look at Figure A. Each number refers to a block of data. A number with an M refers to a mirrored block of that data.
Figure A |
 |
| A simplistic look at how RAID 1E works |
Now, imagine that disk five suffers a failure. Blocks three and eight are stored on that disk, along with the mirrored copies of blocks five and ten. However, the array can suffer this failure since mirrored copies of blocks three and eight are stored on disk one. In theory, you can lose multiple disks in a RAID 1E array as long as the disks are not adjacent. In Figure A, for example, you can lose disks one and three, with disk one's blocks one and six mirrored to disk two, and disk three's blocks two and seven mirrored to disk four."
RAID 1E can potentially provide more performance than a traditional RAID 1 array. With an odd number of disks, RAID 1E provides more spindles (in many RAID 1E cases, three disks/spindles instead of two). Like RAID 1, RAID 1E’s primary disadvantage is its 50 percent disk overhead. Another significant RAID 1E disadvantage is its relatively low support from controller manufacturers.
Summary
RAID 1E looks to be an interesting alternative to RAID 1 when somewhat better performance is necessary, and you don’t want to go the RAID 10 route. Are any of you running systems with RAID 1E? If so, leave a comment and let us know your reasoning and experience.
IBM ServeRAID 1E
La serie de adaptadores IBM ServeRAID soportan un espejado doble de un número arbitrario de discos, como se ilustra en el gráfico.
Esta configuración es tolerante a fallos de unidades no adyacentes. Otros sistemas de almacenamiento como el StorEdge T3 de Sun soportan también este modo.
![]()
¿Que es un Cluster?
Historia de los Sistemas Clusters

Evolución de los clusters
En los primeros clusters de PCs como los sistemas tipo Beowulf se empleaba la tecnología LAN Ethernet existente cuyo costo había mejorado al punto que los clusters armados eran factibles de implementar. Sin embargo, su ancho de banda pico de 10 Mbps era sólo adecuada para las aplicaciones débilmente acopladas y algunos sistemas ensamblaron múltiples redes Ethernet en paralelo a través del software conocido como "canal enlazado" que multiplicaba los canales disponibles en un nodo de forma transparente al código de la aplicación mientras que resultaba un ancho de banda significativamente mayor al que proporcionaba un solo canal.
Esos primeros sistemas estaban lejos de la perfección pero eran útiles. Aún estos primeros clusters exhibían una ventaja precio-rendimiento respecto a las supercomputadoras contemporáneas que se acercaba a un factor de 50 en casos especiales mientras que el rendimiento sostenido por nodo para aplicaciones reales era de un factor que variaba entre 3% y 50% de los sistemas costosos con el mismo número de procesadores. Pero el rápido mejoramiento en el desempeño de los microprocesadores de las PCs y los avances en las redes locales han llevado a los sistemas a un rendimiento de decenas y aún cientos de Gigaflops mientras mantienen excepcionales beneficios precio-rendimiento. Precisamente, con el surgimiento del Fast Ethernet con ancho de banda pico de 100Mbs y la disponibilidad de concentradores a bajo costo y switches a costo moderado, los clusters se volvieron prácticos y fueron útiles para un rango creciente de aplicaciones.
Actualmente, los clusters permiten una flexibilidad de configuración que no se encuentra normalmente en los sistemas multiprocesadores convencionales. El número de nodos, la capacidad de memoria por nodo, el número de procesadores por nodo, y la topología de interconexión, son todos parámetros de la estructura del sistema que puede ser especificada en detalle en una base por nodo sin incurrir en costos adicionales debidos a la configuración personalizada.
Los clusters también permiten una rápida respuesta a las mejoras en la tecnología. Cuando los nuevos dispositivos, incluyendo procesadores, memoria, disco y redes están disponibles se pueden integrar a los nodos del cluster de manera fácil y rápida permitiendo que sean los sistemas paralelos que primero se benefician de tales avances. Lo mismo se cumple para los beneficios de un mejoramiento constante en el rubro de precio-rendimiento en la tecnología. Los clusters son actualmente la mejor opción para seguir la pista de los adelantos tecnológicos y responder rápidamente a las ofertas de nuevos componentes.
Beowulf - El primer cluster de computadoras de escritorio.
El primer cluster fue desarrollado por la NASA y estaba formado por 16 nodos DX4 conectados en una canal ethernet, el máximo poder de procesamiento era de un GigaFLOP (Floting Point Operation/sec.) y se desarrollo como parte del proyecto Beowulf Cluster en el verano de 1994 para el desarrollo en ciencias de la tierra y el espacio.
El proyecto fue iniciado por Thomas Sterling y Don Becker (1994) del Center of Excellence in Space Data and Information Sciences (CESDIS), bajo el patrocinio del Proyecto Earth and Space Sciences (ESS), quienes construyeron éste primer cluster de 16 nodos, conectados por un canal Ethernet a 10 Mbps, al que llamaron Beowulf.
La puesta en marcha de éste primer cluster Beowulf no fue una tarea sencilla ya que se enfrentaron a diferentes problemas, desconocidos hasta entonces. Primero, los procesadores eran demasiado rápidos para las tarjetas de red y los equipos de comunicación. En busca de una solución a este problema, Becker modificó los controladores de las tarjetas Ethernet para el sistema operativo Linux, con el fin de crear un controlador que permitiera distribuir el tráfico de la red en dos o más tarjetas, con la finalidad de balancear el sistema. En aquella época fue necesario realizar este proceso porque se contaba con una red de 10 Mbps y un protocolo de comunicación Ethernet. Migrar a otros protocolos de red más eficientes, implicaba costos muy elevados.
Básicamente, lo que se buscaba era proporcionar a los usuarios sistemas consistentes en componentes que se tenían a disposición o que podían conseguir fácilmente en el mercado cibernético (COTS, por sus siglas en inglés commodity off the shelf), abriendo la posibilidad de satisfacer las necesidades de cómputo paralelo. Esto tuvo un gran éxito y la idea se propagó rápidamente a través de la National Aeronautics and Space Administration (NASA) y los grupos académico y científico. La aceptación inmediata dio origen a lo que se conoció como proyecto Beowulf.
CLUSTER
El término cluster se aplica a los conjuntos o conglomerados de computadoras construidos mediante la utilización de componentes de hardware comunes y que se comportan como si fuesen una única computadora.
El cómputo con clusters surge como resultado de la convergencia de varias tendencias actuales que incluyen la disponibilidad de microprocesadores económicos de alto rendimiento y redes de alta velocidad, el desarrollo de herramientas de software para cómputo distribuido de alto rendimiento, así como la creciente necesidad de potencia computacional para aplicaciones que la requieran.
Simplemente, cluster es un grupo de múltiples ordenadores unidos mediante una red de alta velocidad, de tal forma que el conjunto es visto como un único ordenador, más potente que los comunes de escritorio. De un cluster se espera que presente combinaciones de los siguientes servicios:q
Alto rendimiento (High Performance)
Alta disponibilidad (High Availability)
Equilibrio de carga (Load Balancing)
Escalabilidad (Scalability)
La construcción de los ordenadores del cluster es más fácil y económica debido a su flexibilidad: pueden tener la misma configuración de hardware y sistema operativo (cluster homogéneo), diferente rendimiento pero con arquitecturas y sistemas operativos similares (cluster semi-homogéneo), o tener diferente hardware y sistema operativo (cluster heterogéneo).
Para que un cluster funcione como tal, no basta solo con conectar entre sí los ordenadores, sino que es necesario proveer un sistema de manejo del cluster, el cual se encargue de interactuar con el usuario y los procesos que corren en él para optimizar el funcionamiento.
Componentes de un Cluster
En general, un cluster necesita de varios componentes de software y hardware para poder funcionar. A saber:
Nodos (los ordenadores o servidores)
Sistemas Operativos
Conexiones de Red
Middleware (capa de abstracción entre el usuario y los sistemas operativos)
Protocolos de Comunicación y servicios.
Aplicaciones (pueden ser paralelas o no)
Nodos
Pueden ser simples ordenadores, sistemas multi procesador o estaciones de trabajo (workstations).
Sistema Operativo
Debe ser multiproceso, multiusuario. Otras características deseables son la facilidad de uso y acceso.
Ejemplos:
GNU/Linux
OpenMosix
Rocks (una distribución especializada para clusters).
Kerrighed
Unix: Solaris / HP-Ux / Aix
Windows NT / 2000 / 2003 Server
Mac OS X
Cluster OS's especiales
Conexiones de Red
Los nodos de un cluster pueden conectarse mediante una simple red Ethernet con placas comunes (adaptadores de red o NICs), o utilizarse tecnologías especiales de alta velocidad como Fast Ethernet, Gigabit Ethernet, Myrinet, Infiniband, SCI, etc. Es una red normal que permite conectarse a las computadoras.
Middleware
El middleware es un software que generalmente actúa entre el sistema operativo y las aplicaciones con la finalidad de proveer a un cluster lo siguiente:
una interfaz única de acceso al sistema, denominada SSI (Single System Image), la cual genera la sensación al usuario de que utiliza un único ordenador muy potente;
herramientas para la optimización y mantenimiento del sistema: migración de procesos, checkpoint-restart (congelar uno o varios procesos, mudarlos de servidor y continuar su funcionamiento en el nuevo host), balanceo de carga, tolerancia a fallos, etc.;
escalabilidad: debe poder detectar automáticamente nuevos servidores conectados al cluster para proceder a su utilización.
Existen diversos tipos de middleware, como por ejemplo: MOSIX, OpenMOSIX, Cóndor, OpenSSI, etc.
El middleware recibe los trabajos entrantes al cluster y los redistribuye de manera que el proceso se ejecute más rápido y el sistema no sufra sobrecargas en un servidor. Esto se realiza mediante políticas definidas en el sistema (automáticamente o por un administrador) que le indican dónde y cómo debe distribuir los procesos, por un sistema de monitorización, el cual controla la carga de cada CPU y la cantidad de procesos en él.
El middleware también debe poder migrar procesos entre servidores con distintas finalidades:
balancear la carga: si un servidor está muy cargado de procesos y otro está ocioso, pueden transferirse procesos a este último para liberar de carga al primero y optimizar el funcionamiento;
mantenimiento de servidores: si hay procesos corriendo en un servidor que necesita mantenimiento o una actualización, es posible migrar los procesos a otro servidor y proceder a desconectar del cluster al primero;
priorización de trabajos: en caso de tener varios procesos corriendo en el cluster, pero uno de ellos de mayor importancia que los demás, puede migrarse este proceso a los servidores que posean más o mejores recursos para acelerar su procesamiento.
Concepto de los algoritmos de clustering
El clustering es una técnica estadística que permite una generación automática de grupos en los datos. Incluso, existen algoritmos de clustering que permiten la generación de grupos jerárquicos, consiguiendo una mayor abstracción y representación de la información para poder recuperarla más eficiente.
En cuanto a los factores que influyen en el clustering son:
Propiedades o atributos a gestionar de los objetos que representan el conjunto de datos.
Función matemática que mide la distancia entre dos objetos. Las funciones típicas son la distancia Manhattan, la distancia Euclídea, el producto escalar y demás.
Las restricciones a las que está sujeto el conjunto de datos a clasificar, principalmente una a destacar: la elección del número de clusters: existen muchos criterios y todos ellos basados en heurísticas basadas en el cálculo de distancias entre los objetos.
Uso del clustering en la extracción de información
En la extracción de la información la técnicas basadas en clustering son muy comunes para aquellos casos donde no existan conjuntos de entrenamiento, la información cambia dinámicamente o se pretende extraer propiedades o clases de información.
En el dominio de la extracción de la información se distinguen dos aplicaciones muy útiles:
Extracción de correferencias en los nombres de una frase . Se trata de relacionar nombre y pronombres que se refieren a la misma persona, cosa, lugar, fecha... Por ejemplo, en la frase "Bill Clinton fue a Nigeria para hablar con los trabajadores del SIDA. Después, el presidente de USA y su mujer fueron de viaje a China..." se tiene una primera clase que es Bill Clinton y una serie de nombres y pronombres que le referencian: "el presidente de USA" y "su". Sacar relaciones de texto es un problema NP-duro, pero mediante técnicas de clustering y mediante la adición de restricciones, se puede resolver con bastante menor costo computacional, tanto en tiempo como en memoria.
Correferencias de frases en diferentes documentos. Recuperar cadenas de caracteres en distintos ficheros y que hagan referencia al mismo contexto. Esto es de gran utilidad para los buscadores y recuperadores de información que actualmente incluye el Windows Vista y anteriormente Mac OS, la recuperación de información no sólo consiste en el nombre del archivo, sino que también comprueba la información y el contexto de dentro de cada archivo o fichero.
¿se puede virtualizar todo? Tipos de virtualización
Virtualización es un término amplio que se refiere a la abstracción de los recursos de una computadora. Este término viene siendo usado desde antes de 1960, y ha sido aplicado a diferentes aspectos y ámbitos de la informática, desde sistemas computacionales completos hasta capacidades o componentes individuales. El tema en común de todas las tecnologías de virtualización es la de ocultar los detalles técnicos a través de la encapsulación. Un reciente desarrollo de nuevas plataformas y tecnologías de virtualización han hecho que se vuelva a prestar atención a este maduro concepto. Existen dos tipos de virtualización:
Virtualización de plataforma que involucra la simulación de máquinas virtuales.
Virtualización de recursos que involucra la simulación de recursos combinados, fragmentados o simples.
Virtualización de plataforma
El sentido original del término virtualización es el de la creación de una máquina virtual utilizando una combinación de hardware y software. Para nuestra conveniencia vamos a llamar a esto virtualización de plataforma.
La virtualización de plataforma es llevada a cabo en una plataforma de hardware mediante un software “host” (un programa de control) que simula un entorno computacional (máquina virtual) para su software “guest”. Este software “guest”, que generalmente es un sistema operativo completo, corre como si estuviera instalado en una plataforma de hardware autónoma. Típicamente muchas máquinas virtuales son simuladas en una máquina física dada. Para que el sistema operativo “guest” funcione, la simulación debe ser lo suficientemente robusta como para soportar todas las interfaces externas de los sistemas guest, las cuales pueden incluir (dependiendo del tipo de virtualización) los drivers de hardware.
Existen muchos enfoques a la virtualización de plataformas:
Emulación o simulación: la máquina virtual simula un hardware completo, admitiendo un sistema operativo “guest” sin modificar para una CPU completamente diferente. Este enfoque fue muy utilizado para permitir la creación de software para nuevos procesadores antes de que estuvieran físicamente disponibles. La emulación es puesta en práctica utilizando una variedad de técnicas, desde state machines hasta el uso de la recopilación dinámica en una completa plataforma virtual.q
Virtualización nativa y virtualización completa: la máquina virtual simula un hardware suficiente para permitir un sistema operativo “guest” sin modificar (uno diseñado para la misma CPU) para correr de forma aislada. Típicamente, muchas instancias pueden correr al mismo tiempo. Este enfoque fue el pionero en 1966 con CP-40 y CP[-67]/CMS, predecesores de la familia de máquinas virtuales de IBM. Algunos ejemplos: VMware Workstation, VMware Server, Parallels Desktop, Adeos, Mac-on-Linux, Win4BSD, Win4Lin Pro y z/VM.
Virtualización parcial (y aquí incluimos el llamado “address space virtualization”): la máquina virtual simula múltiples instancias de mucho (pero no de todo) del entorno subyacente del hardware, particularmente address spaces. Este entorno admite compartir recursos y aislar procesos, pero no permite instancias separadas de sistemas operativos “guest”. Aunque no es vista como dentro de la categoría de máquina virtual, históricamente éste fue un importante acercamiento, y fue usado en sistemas como CTSS, el experimental IBM M44/44X, y podría decirse que en sistemas como OS/VS1, OS/VS2 y MVS.
Paravirtualización: la máquina virtual no necesariamente simula un hardware, en cambio ofrece un API especial que solo puede usarse mediante la modificación del sistema operativo “guest”. La llamada del sistema al hipervisor tiene el nombre de “hypercall” en Xen y Parallels Workstation; está implementada vía el hardware instruction DIAG (“diagnose”) en el CMS de VM en el caso de IBM (este fue el origen del término hypervisor). Ejemplo: VMware ESX Server, Win4Lin 9x y z/VM.
Virtualización a nivel del sistema operativo: virtualizar un servidor físico a nivel del sistema operativo permitiendo múltiples servidores virtuales aislados y seguros correr en un solo servidor físico. El entorno del sistema operativo “guest” comparte el mismo sistema operativo que el del sistema “host” (el mismo kernel del sistema operativo es usado para implementar el entorno del “guest”). Las aplicaciones que corren en un entorno “guest” dado lo ven como un sistema autónomo. Ejemplos: Linux-VServer, Virtuozzo, OpenVZ, Solaris Containers y FreeBSD Jails.
Virtualización de aplicaciones: consiste en el hecho de correr una desktop o una aplicación de server localmente, usando los recursos locales, en una máquina virtual apropiada. Esto contrasta con correr la aplicación como un software local convencional (software que fueron “instalados” en el sistema). Semejantes aplicaciones virtuales corren en un pequeño entorno virtual que contienen los componentes necesarios para ejecutar, como entradas de registros, archivos, entornos variables, elementos de uso de interfaces y objetos globales. Este entorno virtual actúa como una capa entre la aplicación y el sistema operativo, y elimina los conflictos entre aplicaciones y entre las aplicaciones y el sistema operativo. Los ejemplos incluyen el ]]Java Virtual Machine]] de Sun, Softricity, Thinstall, Altiris y Trigence (esta metodología de virtualización es claramente diferente a las anteriores; solo una pequeña línea divisoria los separa de entornos de máquinas virtuales como Smalltalk, FORTH, Tel, P-code).
Virtualización de los recursos
El concepto básico de la virtualización de plataforma, descrita anteriormente, se extendió a la virtualización de recursos específicos del sistema como la capacidad de almacenamiento, nombre de los espacios y recursos de la red.
Los términos resource aggregation, spanning o concatenation (name spaces) se utiliza cuando se combinan componentes individuales en un mayor recurso o en un recurso de uso común (resource pools). Por ejemplo:
RAID y volume managers combinan muchos discos en un gran disco lógico.
La Virtualización de almacenamiento (Storage virtualization) refiere al proceso de abstraer el almacenamiento lógico del almacenamiento físico, y es comúnmente usado en SANs (Storage Area Network). Los recursos de almacenamientos físicos son agregados al storage pool, del cual es creado el almacenamiento lógico. Múltiples dispositivos de almacenamiento independientes, que pueden estar dispersos en la red, le aparecen al usuario como un dispositivo de almacenamiento independiente del lugar físico, monolítico y que puede ser administrado centralmente.
Channel bonding y el equipamiento de red utilizan para trabajar múltiples enlaces combinados mientras ofrecen un enlace único y con mayor amplitud de banda.
Red privada virtual (en inglés Virtual Private Network, VPN), Traducción de dirección de red (en inglés Network Address Translation, NAT) y tecnologías de red similares crean una red virtual dentro o a través de subredes.
Sistemas de computación multiprocessor y multi-core muchas veces presentan lo que aparece como un procesador único, rápido e independiente.
Cluster grid computing y servidores virtuales usan las tecnologías anteriormente mencionadas para combinar múltiples y diferentes computadoras en una gran metacomputadora.
Particionamiento es la división de un solo recurso (generalmente grande), como en espacio de disco o ancho de banda de la red, en un número más pequeño y con recursos del mismo tipo más fáciles de utilizar. Esto es muchas veces llamado “zoning”, especialmente en almacenamiento de red.
Encapsulación es el ocultamiento de los recursos complejos mediante la creación de un interfaz simple. Por ejemplo, muchas veces CPUs incorporan memoria caché o segmentación (pipeline) para mejorar el rendimiento, pero estos elementos no son reflejados en su interfaz virtual externa. Interfaces virtuales similares que ocultan implementaciones complejas se encuentran en los discos, módems, routers y otros dispositivos “inteligentes” (smart).
Redundant and RAID 6
Redundant and RAID 6
The drives are connected by dual SAS controllers with RAID 6 data protection. With RAID 5, you can recover your data by rebuilding the RAID array after one drive fails. But if you lose a second drive while you are rebuilding the array – or if you accidentally remove the wrong drive before you start the rebuild – you could lose data. RAID 6 adds a second parity stripe across each element of the array, giving you a second level of protection. One drive in the RAID set may fail but it’s far less likely that two drives will; and when a drive fails, the data is still protected even while you’re rebuilding the array.
This adds up to a fully dual redundant switched fabric between the blades and the storage, although Callahan won’t yet go into details about the technology. “There are dual paths to each drive, dual controllers fronting each drive, dual paths from the controller to the blades, dual switches in the blade chassis and dual connections from the switches to the blade,” Callahan said.
The SAS switch in the ExDS9100 means you don’t need external switches, interconnects or extra cabling within the data center. Avoiding fibre channel helps keep the overall cost down, and HP says it uses its buying power to keep the disk prices low. Current enterprise storage costs are around $15 per gigabyte, while HP promises the ExDS9100 will be “dramatically cheaper” than the other storage it sells, costing less than $2/GB. That still adds up to $500,000 for the standard 246TB or $1.64 million for 820TB.
Callahan predicts costs will continue to drop to a price of 11 cents per GB by 2011 for spinning disks and under a dollar for the same amount of solid state drive media, while adding that HP is working on “lots of interesting I things can’t talk about now."
But when you’re pricing a petabyte system, it’s not just the purchase price that matters, it’s how much it will cost to keep it running. Multiple petabytes of storage mean there will be many thousands of spinning disks, some of which will fail. Distributed software and RAID protect data in case of disk failure, but you’ll still have to replace failed parts. Designing a system that makes it quicker and simpler to replace failed disks will thus save costs because you don’t need as much staff to run the system.
When drives or the fans in the disk enclosures fail, the PolyServe software tells you which one has failed and where – and gives you the part number for ordering a replacement. Add a new blade or replace one that’s failed and you don’t need to install software manually. When the system detects the new blade, it configures it automatically. That involves imaging it with the Linux OS, the PolyServe storage software and any apps you have chosen to run on the ExDS; booting the new blade; and adding it to the cluster. This is all done automatically. Automatically scaling the system down when you don’t need as much performance as you do during heavy server-load periods or marking data that doesn’t need to be accessed as often, also keeps costs down.
HP packs drives together more densely than most storage arrays, manages them with PolyServe to cut the costs of running the array and uses its buying power to push down the cost of the individual drives as well. Power usage and cooling needs are well within the range of what modern data centers can deliver, says Callahan but he admits that’s high, joking that “it also makes a great space heater.”
One option for reducing power and cooling costs is MAID, which comprises massive arrays of inactive disks that power down most of the drives most of the time. The first generation of ExDS does use MAID, but Callahan says HP is looking at the options. “Obviously it would be a nice idea, if you have a lot of drives in an environment, to not to have to spin all of them all the time,” Callahan said. “In the first release, though, we do spin all of them all the time.”


![]()
Diagrama de una configuración RAID 6. Cada número representa un bloque de datos; cada columna, un disco; p y q, códigos Reed-Solomon.
Un RAID 6 amplía el nivel RAID 5 añadiendo otro bloque de paridad, por lo que divide los datos a nivel de bloques y distribuye los dos bloques de paridad entre todos los miembros del conjunto. El RAID 6 no era uno de los niveles RAID originales.
El RAID 6 puede ser considerado un caso especial de código Reed-Solomon.1 El RAID 6, siendo un caso degenerado, exige sólo sumas en el campo de Galois. Dado que se está operando sobre bits, lo que se usa es un campo binario de Galois (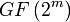 ). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR.
). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR.
Tras comprender el RAID 6 como caso especial de un código Reed-Solomon, se puede ver que es posible ampliar este enfoque para generar redundancia simplemente produciendo otro código, típicamente un polinomio en 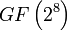 (m = 8 significa que estamos operando sobre bytes). Al añadir códigos adicionales es posible alcanzar cualquier número de discos redundantes, y recuperarse de un fallo de ese mismo número de discos en cualesquiera puntos del conjunto, pero en el nivel RAID 6 se usan dos únicos códigos.
(m = 8 significa que estamos operando sobre bytes). Al añadir códigos adicionales es posible alcanzar cualquier número de discos redundantes, y recuperarse de un fallo de ese mismo número de discos en cualesquiera puntos del conjunto, pero en el nivel RAID 6 se usan dos únicos códigos.
Al igual que en el RAID 5, en el RAID 6 la paridad se distribuye en divisiones (stripes), con los bloques de paridad en un lugar diferente en cada división.
El RAID 6 es ineficiente cuando se usa un pequeño número de discos pero a medida que el conjunto crece y se dispone de más discos la pérdida en capacidad de almacenamiento se hace menos importante, creciendo al mismo tiempo la probabilidad de que dos discos fallen simultáneamente. El RAID 6 proporciona protección contra fallos dobles de discos y contra fallos cuando se está reconstruyendo un disco. En caso de que sólo tengamos un conjunto puede ser más adecuado que usar un RAID 5 con un disco de reserva (hot spare).
La capacidad de datos de un conjunto RAID 6 es n-2, siendo n el número total de discos del conjunto.
Un RAID 6 no penaliza el rendimiento de las operaciones de lectura, pero sí el de las de escritura debido al proceso que exigen los cálculos adicionales de paridad. Esta penalización puede minimizarse agrupando las escrituras en el menos número posible de divisiones (stripes), lo que puede lograrse mediante el uso de un sistema de ficheros WAFL.
miércoles, 7 de enero de 2009
Historia de Unix
Historia de Unix
Desde que comenzó a difundirse desde los Laboratorios Bell de AT&T a comienzos de la década de 1970, el éxito del sistema operativo Unix ha dado lugar a una gran cantidad de versiones diferentes: los que recibieron el (en ese tiempo gratis) código del sistema Unix, todos comenzaron a desarrollar sus propias versiones diferentes por sus propias, diferentes, vías para uso y venta. Universidades, institutos de investigación, cuerpos del gobierno y compañías de computación, todos comenzaron usando el poderoso sistema Unix para desarrollar muchas de las tecnologías las cuales hoy son parte de un sistema Unix.
Diseño asistido por computadora, sistemas de control de manufactura, simulaciones de laboratorio, aun el Internet mismo, todos comenzaron a vivir con y por los sistemas Unix. Hoy, sin los sistemas Unix, el Internet llegaría a un paro alarmante. ¡Muchas llamadas de teléfono no podrían ser hechas, el comercio electrónico sería presionado a pararse y nunca habría habido "Jurassic Park"!
A finales de la década de 1970, un efecto de onda entró en juego. Por el momento los estudiantes pre- y post-graduados cuyo trabajo de laboratorio ha explorado estas nuevas aplicaciones de tecnología alcanzaron posiciones de manejo y toma de decisiones dentro de los abastecedores de sistemas de computación y entre sus clientes. Y ellos, quisieron seguir usando sistemas Unix.
Pronto todos los grandes vendedores, y muchos de los más pequeños, estuvieron mercadeando sus propias, divergentes, versiones del sistema Unix optimizado para sus propias arquitecturas de computadora y luciendo muchas diferentes fortalezas y características. Los clientes encontraron que, aunque los sistemas Unix estaban disponible en todo lugar, ellos raramente fueron capaces de trabajar en grupo o co-existir sin destinar significativamente tiempo y esfuerzo para hacer que ellos trabajaran efectivamente. La marca registrada Unix era ubicua, pero ella fue aplicada a una multitud de diferentes e incompatibles productos.
A comienzos de la década de 1980, el mercado de los sistemas Unix ha crecido suficiente para ser notado por los analistas de la industria e investigadores. Entonces la pregunta ya no fue "¿Que es un sistema Unix?" sino "¿Es un sistema Unix satisfactorio para negocios y comercio?".
Desde el comiezo de la década de 1980 y la mitad de ésta, el debate sobre las fortalezas y debilidades de los sistemas Unix se propagó, frecuentemente recargado por las manifestaciones de los mismos vendedores quienes idearon proteger las ventas de sus sistemas propietarios rentables, proponiendo el desuso del sistema Unix. Y en un esfuerzo por diferenciar más sus propios productos de sus sistemas Unix, ellos se mantuvieron desarrollando y añadiendo características por su propia cuenta.
En 1984, otro factor trajo una atención adicional a los sistemas Unix. Un grupo de vendedores preocupados por el contínuo usurpamiento en sus mercados y el control de interfaces de sistemas por las grandes compañías, desarrollaron el concepto de "sistemas abiertos".
Los sistemas abiertos fueron aquellos que se encontrarían de acuerdo con especificaciones o estándares. Esto resultó en la formación de X/Open Company Ltd cuya remisión fue, y hoy permanece en la guisa de The Open Group, para definir un ambiente de sistemas abiertos comprehensivo. Los sistemas abiertos, declararon, ahorrarían en costos, atraerían una más amplia carpeta de aplicaciones y competición en términos iguales. X/Open escogió el sistema Unix como la plataforma para la base de los sistemas abiertos.
Aunque Unix todavía lo poseía AT&T, la compañía hizo poco comercialmente con él hasta mediados de la década de 1980. Entonces el foco de luz de X/Open mostró claramente que una versión simple y estándar del sistema Unix estaría en los amplios intereses de la industria y sus clientes. La pregunta era ahora "¿cuál versión?".
En un movimiento previsto a unificar el mercado en 1987, AT&T anunció un pacto con Sun Microsystems, el líder proponente de la versión de Unix derivada de Berkeley. Sin embargo, el resto de la industria vió el desarrollo con considerable preocupación. Creyendo que sus propios mercados estaban amenazados ellos se asociaron entre sí para desarrollar su propio "nuevo" sistema operativo de sistemas abiertos. Su nueva organización se llamó la Open Software Foundation (OSF). En respuesta a esto, la facción AT&T/Sun formó Unix International.
La "guerra de Unix" resultante dividió a los vendedores de sistemas entre estos dos campos agrupados alrededor de las dos tecnologías dominantes de sistemas Unix: el System V de AT&T y el sistema OSF llamado OSF/1. Entretanto, X/Open Company se mantuvo firme. Ella continuó el proceso de estandarización de los APIs necesarios para una especificación de un sistema operativo abierto.
Adicionalmente, ella buscó en áreas del sistema más allá del nivel del sistema operativo donde un enfoque estándar añadiría valor tanto para el abastecedor como para el cliente, desarrollando o adoptando especificaciones para lenguajes, conectividad de base de datos, interconexión de redes y trabajo colaborativo en mainframes. El resultado de este trabajo fue publicado en sucesivas Guías de Portabilidad de X/Open.
XPG 4 fue lanzado en Octubre de 1992. Durante este tiempo. X/Open ha ubicado un programa de marca basado en garantías del vendedor y soportado por pruebas. Desde la publicación de XPG4, X/Open ha continuado la ampliación del alcance de las especificaciones de sistemas abiertos en línea con los requerimientos del mercado. A medida que los beneficios de la marca X/Open llegaron a ser conocidos y comprendidos, muchas organizaciones grandes comenzaron a usarr X/Open como la base para el diseño y logro de sistemas. Hacia 1993, sobre 7 billones de dólares han sido destinados en sistemas marcados X/Open. Hacia el comienzo de 1997 esa figura ha ascendido sobre los 23 billones de dólares. A la fecha, los logros referenciando la Simple especificación Unix asciende sobre los 5.2 billones de dólares.
A comienzos de 1993, AT&T vendió su Laboratorio de Sistemas Unix a Novell quien estuvo buscando un sistema operativo peso pesado para enlazarlo a su rango de productos NetWare. Al mismo tiempo, la compañía reconoció que estableciendo el control de la definición (especificación) y la marca registrada con una organización de vendedores-neutral facilitaría mucho más el valor de Unix como una fundación de sistemas abiertos. De esta manera las partes constituyentes del Sistema Unix, previamente poseídas por una simple entidad están ahora bastante separadas.
En 1995 SCO compró el negocio de los Sistemas Unix de Novell, y el código fuente y tecnología del sistema pasa a ser desarrollada por SCO.
En 1995 X/Open introdujo la marca Unix 95 para sistemas de computación que garantizan cumplir con la Especificación Simple de Unix. El programa de la marca de Especificación Simple de Unix ha alcanzado ahora una masa crítica: los vendedores cuyos productos han cumplido los criterios de demanda son considerados ahora en la mayoría de sistemas Unix de valor.
Durante diez años, desde el inicio de X/Open, Unix ha estado íntimamente conectado con sistemas abiertos. X/Open, ahora parte del Open Group, continúa para desarrollar y evolucionar la Especificación Simple de Unix y el programa de marca asociado en beneficio de la comunidad IT. La liberación de la especificación de las interfaces de la tecnología está permitiendo a muchos sistemas soportar la filosofía de Unix de herramientas pequeñas, frecuentemente simples, que pueden ser combinadas de muchas maneras para realizar frecuentemente tareas complejas. La estabilidad de las interfaces del kernel preservan las inversiones existentes, y está permitiendo el desarrollo de un conjunto rico de herramientas de software. El movimiento Open Source se está construyendo en esta fundación estable y está creando un resurgimiento de entusiasmo por la filosofía Unix. De muchas maneras Open Source puede ser visto como la verdadera entrega de Sistemas Abiertos que asegurará que ellos continúen siendo fuertes de extremo a extremo.
Cronografia
La Universidad de California en Berkeley comenzó sus desarrollos en el campo UNIX, añadiendo nuevas características y haciendo modificaciones. Así, en 1975 Ken Thompson promovió el desarrollo y sacó a la luz su propia versión de UNIX, conocida como BSD. Desde entonces BSD pasó a convertirse en la gran competidora de los laboratorios Bell. En esta versión contribuyeron Bill Joy y Chuck Haley, sus contribuciones son numerosas pero entre ellas destacan un compilador de Pascal, el editor vi, el editor ex y el Shell C. Más tarde, a principios de los 80, se produjo el lanzamiento de Sistema III, la primera versión comercial del sistema operativo UNIX. En 1983 AT&T introdujo el UNIX Sistema V versión 1. EN 1983 Berkeley lanza una poderosa versión UNIX conocida como BSD versión 4.2 Entre sus características principales se encuentran la gestión de archivos muy sofisticada así como la posibilidad de trabajo en redes basadas en los protocolos TCP/IP ( los mismos que hoy en día se utilizan en internet ). Esta versión de UNIX la adoptaron varios fabricantes, entre ellos Sun Microsystems, lo que dió lugar al conocido sitema SunOS. En aquellos momentos las diferencias entre versiones de UNIX eran muy grandes, lo que provocaba verdaderos quebraderos dde cabezas para los programadores. Principales variantes de UNIX en la actualidad En la actualidad las versiones de UNIX más difundidas son las siguientes: Solaris: Es el nombre con el que se conoce el sistema operativo de Sun Microsystems. Originalmente se llamó SunOS, pero posteriormente, debido a la presentación de UNIX Sistema V se desarrolló una nueva versión a la que se le llamó Solaris. Existen versiones de Solaris para Power PC, Intel y Sparc. AIX: La versión del sistema operaivo UNIX para las máquinas IBM se llama AIX y está basada en Sistema V versión 3 y BSD 4.3. A/UX: Implementación de UNIX de Apple IRIX: Versión de UNIX desarrollada por Silicon Graphics para sus estaciones basada en UNIX Sistema V version 4. SCO UNIX: Es la versión de Santa Cruz Operation (SCO), versión de UNIX Sistema V diseñada para plataformas Intel. Linux: Empezó como un simple proyecto de Linus Torlvalds, como todos sabéis, un estudiante de la universidad de Helsinki a principio de los años 90. En la actualidad se ha difundido enormemente por todo el planeta y lo usan millones de usuarios, tanto particulares como grandes empresas.1969